التعلم المعزز (Reinforcement Learning) هو فرع من الذكاء الاصطناعي الذي يركز على كيفية تعلم الآلات اتخاذ القرارات من خلال التفاعل مع بيئتها. يختلف التعلم المعزز عن أنواع أخرى من التعلم الآلي مثل التعلم supervised (المراقب) والتعلم unsupervised (غير المراقب) حيث لا يتطلب بيانات مُعلَّمة مسبقًا. بدلاً من ذلك، يعتمد التعلم المعزز على التفاعل المستمر مع البيئة وتعلم الاستراتيجيات التي تؤدي إلى تحقيق أقصى مكافآت.
ما هو التعلم المعزز؟
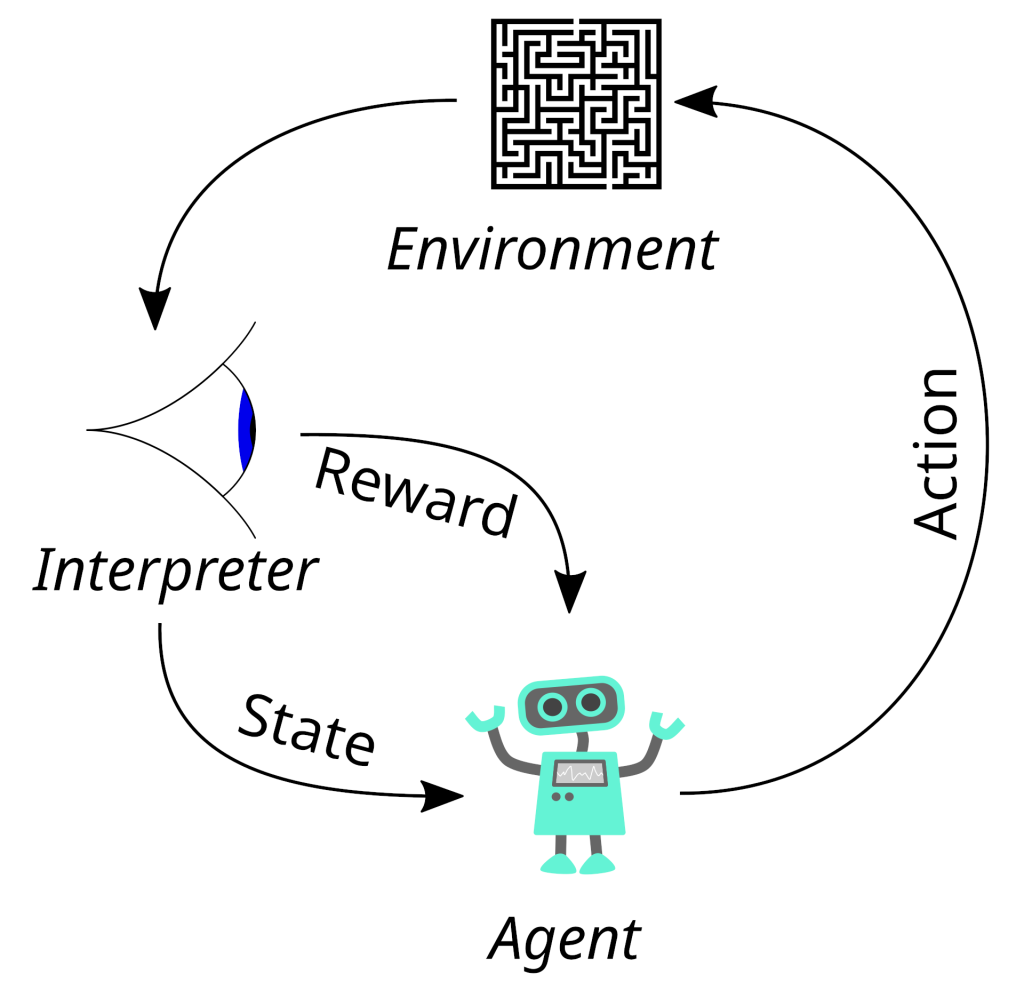
التعلم المعزز هو عملية تعلم تهدف إلى تمكين آلة أو وكيل (Agent) من اتخاذ قرارات تتضمن تحسين الأداء من خلال التجربة والخطأ. في هذه العملية، يتعلم الوكيل كيفية تحقيق أقصى مكافأة من خلال اتخاذ سلسلة من القرارات ضمن بيئة معينة. يتم ذلك من خلال تكرار التفاعل مع البيئة، حيث يتلقى الوكيل ملاحظات في شكل مكافآت أو عقوبات بناءً على أفعاله.
كيفية عمل التعلم المعزز
تعمل عملية التعلم المعزز من خلال عدة خطوات رئيسية:
1.تحديد البيئة (Environment):
البيئة هي كل ما يتفاعل معه الوكيل. يمكن أن تكون البيئة في أي شكل، مثل لعبة شطرنج أو نظام روبوتي أو حتى سوق مالي.
2.تعريف الوكيل (Agent):
الوكيل هو الكيان الذي يتخذ القرارات في البيئة. يتفاعل الوكيل مع البيئة من خلال تنفيذ أفعال (Actions) بناءً على استراتيجيات محددة.
3.اختيار الأفعال (Actions):
يختار الوكيل الأفعال التي سيقوم بها بناءً على حالة البيئة الحالية. يتعلم الوكيل كيفية اختيار الأفعال التي تؤدي إلى تحقيق أعلى مكافآت من خلال التجربة.


4.تلقي المكافآت والعقوبات (Rewards and Penalties):
بعد تنفيذ فعل معين، يتلقى الوكيل ملاحظات في شكل مكافآت أو عقوبات من البيئة. هذه الملاحظات تساعد الوكيل على تقييم جودة أفعاله وتعديل استراتيجيته بناءً على ذلك.
5.تحديث الاستراتيجية (Policy):
الاستراتيجية هي قاعدة تحدد كيفية اختيار الأفعال بناءً على الحالة الحالية. يقوم الوكيل بتحديث استراتيجيته بشكل مستمر لتحسين أدائه وزيادة المكافآت.
خوارزميات التعلم المعزز الرئيسية
1.خوارزمية Q-Learning:
Q-Learning هي واحدة من أبرز خوارزميات التعلم المعزز، وهي تعتمد على تقييم الأفعال بناءً على قيم Q. يقوم الوكيل بتحديث قيم Q لكل فعل بناءً على المكافآت المستلمة، مما يساعد في تحديد الأفعال التي تؤدي إلى أفضل النتائج على المدى الطويل.
2.خوارزمية SARSA (State-Action-Reward-State-Action):
مشابهة لـ Q-Learning، تعتمد SARSA على تحديث القيم بناءً على أفعال الوكيل في كل حالة معينة. الفارق الرئيسي هو أن SARSA تستخدم الأفعال الفعلية التي يتم اختيارها بدلاً من الأفعال المثلى المحتملة.
3.خوارزمية Actor-Critic:
تجمع خوارزمية Actor-Critic بين نوعين من النماذج: الممثل (Actor) والنقد (Critic). يقوم الممثل باختيار الأفعال بناءً على الاستراتيجية، بينما يقوم النقد بتقييم جودة الأفعال ومساعدة الممثل في تحسين استراتيجيته.
4.شبكات Q (Deep Q Networks – DQN):
تستخدم شبكات Q العميقة لتقريب قيم Q من خلال الشبكات العصبية العميقة. تتيح هذه التقنية التعامل مع بيئات معقدة تحتوي على حالات متعددة وأفعال متداخلة.
تطبيقات التعلم المعزز
1.الألعاب:
يتم استخدام التعلم المعزز لتدريب وكيل على لعب الألعاب مثل الشطرنج والألعاب الإلكترونية، حيث يمكن للوكيل تعلم استراتيجيات معقدة من خلال التجربة.
2.الروبوتات:
يُستخدم التعلم المعزز في تدريب الروبوتات على أداء مهام معينة مثل المشي والتقاط الأشياء والتفاعل مع البيئة بشكل مستقل.
3.الأنظمة المالية:
يُستخدم التعلم المعزز لتحسين استراتيجيات التداول واتخاذ القرارات في الأسواق المالية من خلال تحليل البيانات والتفاعل مع السوق.
4.الأنظمة الذكية:
يمكن استخدام التعلم المعزز لتحسين أنظمة التوصية وإدارة المخزون وتحسين تجربة المستخدم في التطبيقات المختلفة.

التحديات والاعتبارات
رغم الفوائد الكبيرة للتعلم المعزز، إلا أن هناك عدة تحديات واعتبارات تشمل:
1.حجم البيانات والموارد:
تتطلب خوارزميات التعلم المعزز كميات كبيرة من البيانات والموارد الحاسوبية لتدريب النماذج بفعالية.
2.التوازن بين الاستكشاف والاستغلال:
يجب على الوكيل تحقيق توازن بين استكشاف أفعال جديدة وتحسين الاستراتيجيات الحالية لتحقيق أقصى مكافأة.
3.تحديات في البيئة الواقعية:
قد تكون البيئات الواقعية أكثر تعقيدًا وصعوبة من البيئات التجريبية، مما يجعل تدريب الوكلاء وتطبيقهم في الواقع أكثر تحديًا.
التعلم المعزز هو مجال متقدم في الذكاء الاصطناعي يتيح للآلات تعلم اتخاذ القرارات من خلال التفاعل مع بيئتها وتحقيق أقصى مكافآت. من خلال تقنيات مثل Q-Learning وSARSA وActor-Critic، يمكن للوكيل تحسين استراتيجيته بمرور الوقت لتحقيق أداء أفضل. على الرغم من التحديات، فإن التعلم المعزز لديه إمكانيات واسعة في تطبيقات متنوعة مثل الألعاب والروبوتات والأنظمة المالية، ويستمر في تطوير تقنيات جديدة لتحسين قدرات الذكاء الاصطناعي.



